
A bit more than a year ago, the UNL Libraries implemented a new platform (TIND) for UNL’s data repository, SANDY. This change from the previous software (Rosetta) allowed us to better standardize and enrich the metadata accompanying each dataset deposited, by including
- ORCIDs for those contributing to the research,
- RORs for associated institutions,
- RRIDs for UNL core facilities involved,
- IRB numbers where appropriate,
- funding sources and grant numbers, and
- related resources such as journal articles (see Figure 1).
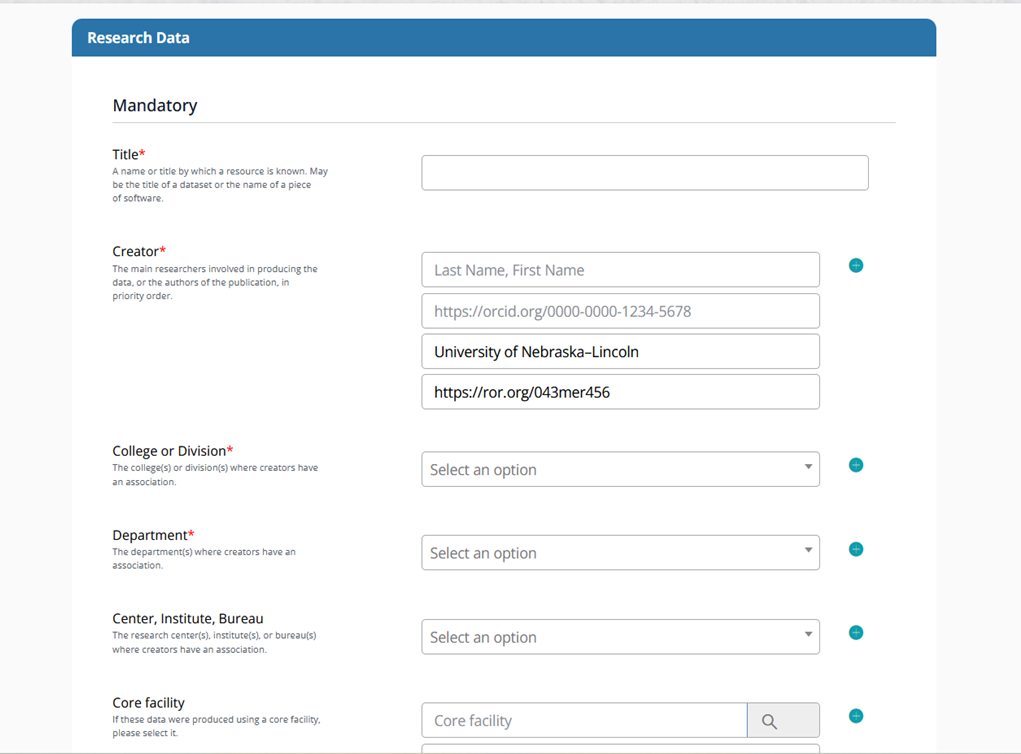
Figure 1. Screenshot of the initial metadata fields of SANDY’s deposit template
Each dataset is assigned a DOI (digital object identifier), a persistent identifier that can be included in associated research outputs to point to the underlying data. Researchers can track downloads of the dataset from SANDY to include as an estimate of impact.
We also have been reviewing and remediating those datasets deposited in the former UNL Data Repository (UNLDR), adding additional detail to the metadata, checking for file integrity, adding related publications, and in a few cases, creating a second version of the deposit for increased value. Regarding the latter area, the UNL Libraries’ membership in the Data Curation Network (DCN) is invaluable. Drawing from the DCN curators’ expertise in a range of disciplines/subjects and data types has improved several ‘lightly curated’ older datasets.
We invite you to consult with the research data services team about depositing data with SANDY, identifying alternative repositories, or requesting assistance with metadata preparation before data submission (whether to SANDY or another repository). Please contact us at datamanagement@unl.edu.